Zöld a fű, kék az ég, savanyú a citrom – a végtelenig sorolhatnánk a józanész-bölcsesség gyűjtőkategóriába tartozó egyértelmű állításokat, tényeket. Persze a fű kiszáradhat, az ég elsötétedhet, a citromot megédesíthetjük, kora gyerekkorunkban viszont megkérdőjelezhetetlen alapállapotukban zöldként, kékként és savanyúként raktározódtak el tudatunk mélyén.
De mi is tulajdonképpen a mesterségesintelligencia-kutatás kezdetétől sokáig az általános MI-ig vezető út legüdvözítőbb módszerének, egyben az MI „sötét anyagának” is tartott józanész-bölcsesség, és miért nem sikerül megtanítani rá a gépeket? Egyrészt, mert könnyebb állításokról megállapítani, hogy igazak vagy hamisak, mint magát a fogalmat definiálni. Az igazsághoz akkor járunk a legközelebb, ha egyfajta széleskörű, nem speciális területekre vonatkozó, bármikor felhasználható, kötelező háttérismeretek táraként határozzuk meg. Tehetetlenek lennénk nélkülük, mert az égvilágon semmit nem értenénk a környező valóságból.

A legtöbb józanész-bölcsességet implicit természete miatt borzasztó nehéz explicit módon megjeleníteni, a két és négyéves kor között megszerzett tudást mégsem írjuk jegyzetfüzetbe. Az MI-kutatások kezdetén viszont hasonlóval próbálkoztak, elvileg a világra vonatkozó összes ismeretet, többmillió vagy többmilliárd állítást próbálták tudásbázisokba másolni, a gépi rendszereknek pedig e bázisokra hagyatkozva kellett volna működniük. Ez lenne az első lépés a józanész-alapú következtetés automatizálása felé.
A józanész-következtetés a következő példával szemléltethető: „süteményt sütök, mert azt akarom, hogy az emberek süteményt egyenek.” Az emberek süteményt esznek a bölcsesség, és ezért sütök sütit a következtetés. (És most tekintsünk el az ilyen-olyan étrendi megfontolásoktól.)
Az ismeretbázishoz kapcsolt természetesnyelv-feldolgozással elvileg gépeknek is efféle következtetéseket kellene levonniuk. Másrészt, a mindennapi objektumokra vonatkozó tudással a hiányos információ problémáját szintén kezelniük kellene. Például, ha tudjuk, hogy „Csacsogó egy madár”, akkor anélkül, hogy bármiféle információval rendelkeznénk Csacsogóról, a madarak zömére érvényes józanész-bölcsesség alapján megállapíthatjuk: „Csacsogó tud repülni.” (Ha Csacsogó pingvin, akkor pechünk van.)
A tudásbázis mellé agyunknak ezt az adottságát kellene a gépi rendszereknek szimulálniuk. Így értenék meg az ok-okozati összefüggéseket is, és általánosabb értelemben is tudnák hasznosítani következtetőkészségüket.
Az MI-kutatás egyik úttörője, John McCarthy már 1959-ben megpróbálkozott vele, de Tanácsadója és az azóta eltelt bő hatvan év józanész-alapú mesterséges intelligenciái, ugyan eltérő mértékben, viszont egytől egyig mind kudarcnak bizonyultak. Az emberrel összehasonlítva, pocsékul teljesítenek a csak az ezeket a triviális ismereteket igénylő feladatok végrehajtásában. Az összes MI-megközelítéshez hasonlóan, a józanész-bölcsességeken alapuló rendszerek is szűkebb területeken értek csak el jó részeredményeket.
Minél szűkebb és minél inkább körülhatárolható, számszerűsíthető az adott terület, annál jobbakat (például a természetesnyelv-feldolgozásban vagy a diagnosztika automatizálásában).
Az MI-történelem legnagyobb szabású józanész-kezdeményezése Douglas Lenat 1984-ben indult – és az IBM Watson elődjének is tekintett, ellentmondásos megítélésű – Cyc-projektje. A cím a beszédes encyclopedia szóra utal, az összes hétköznapi ismeretet lefedő tudásbázis létrehozása volt az eredeti cél. Lenat átlagos szinonimaszótárhoz hasonló, fogalmakból, kategóriákból álló alap tervezésével kezdte. A fogalmak különböző tárgyakat és jelenségeket tartalmaznak. Minden egyes keretbe odaillő állítások kerültek. Az állításokat – ellentéteikkel, s az ellentéteket feloldó más állításokkal együtt – kategóriákba rendezték. Így Cyc tudja például, hogy Drakula vámpír volt, meg azt is, hogy vámpírok nincsenek. Ehhez viszont azt szintén kell tudnia, hogy az első állítás képzelt, míg a második a fizikai valóságban igaz. Hogy eljusson idáig, az összes állítást kontextusba helyezte (fikció kontra tény stb.). Első körben Cyc 400 állítást reprezentált, ma már többmillió fogalmat és gyűjteményt, valamint kb. 25 millió állítást tartalmaz.
A döbbenetes számok ellenére a Cyc minimális hatással van a jelenlegi MI-kutatásokra. Egy ilyen enciklopédia törvényszerűen rengeteg tipikus állítást tartalmaz, a potenciális kivételekkel, szokatlan helyzetekkel viszont nem foglalkozik. Például, ha azt olvassuk, hogy „egy ember étterembe ment, rendelt egy steaket, majd busás borravalót hagyott”, természetesnek vesszük, hogy megette a steaket, pedig senki nem állította. Akár hozzá is vághatta valakihez, becsomagoltathatta, ottani kutyának adhatta stb. Az MI színtisztán szimbolikus, tudásbázis-alapú megközelítései, köztük a Cyc, ezért is sikertelenségre ítélt, túl messzire nem, az általános MI-hez egész biztosan nem vezető kísérletek.
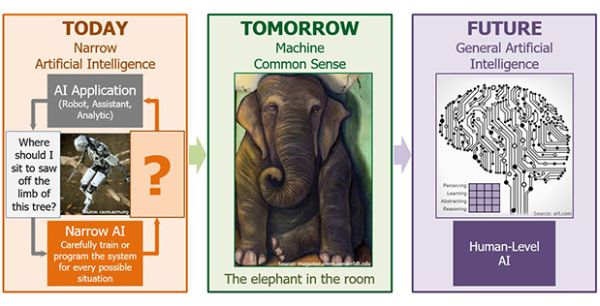 Mostanában többen próbálkoznak a klasszikus józanész-megközelítés és a mélytanulás fúzióján, születnek részsikerek, és bizakodnak, hogy eredményesebbek lesznek.
Mostanában többen próbálkoznak a klasszikus józanész-megközelítés és a mélytanulás fúzióján, születnek részsikerek, és bizakodnak, hogy eredményesebbek lesznek.
:Frissítve 2025. június 9.