A tanulás alapvető folyamat a valamilyen szintű értelemmel rendelkező biológiai lényeknél. A számítástudomány bebizonyította: nemcsak az emberek és az állatok, de gépek is képesek tanulni.
Ugyan másként, mint az élővilág erre alkalmas szereplői, tudásukat viszont akár mesterségesen intelligens programok is folyamatosan gyarapíthatják.
De hogyan?
A számítástudomány egyik legfontosabb mai ága az „új mesterséges intelligenciának” is hívott gépi tanulás. Főként azért nevezik így, mert ma ez az MI legnépszerűbb, legismertebb területe.
A kifejezést Arthur Lee Samuel, az IBM kutatója találta ki 1959-ben. Samuel abból indult ki, hogy a nehezen vagy egyáltalán nem változtatható utasítások, parancsok helyett, egy program a természetből, főként az evolúciótól, és annak eddigi (tudtunk szerinti) koronájától, a Homo sapienstől ellesett modellekből okosodhat.
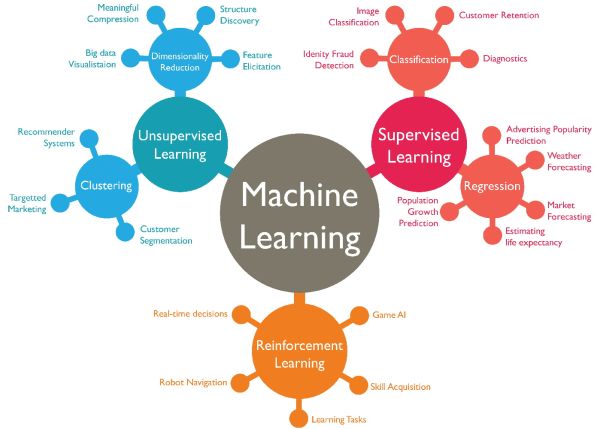
Ezt emberi felügyelettel vagy felügyelet nélkül egyaránt megteheti, megerősítéses tanulásnál pedig maga a rendszer jutalmazza, vagy, ha kell, bünteti az algoritmus teljesítményét. A gép a megtanultak alapján alkalmazkodik a környezetéhez, nem követi el többször ugyanazokat a hibákat. Szűkebb értelemben információkat kivonatol adatokból, mintázatokat, szabályszerűségeket fedez fel bennük, és döntéseket is hoz.
A terület a számítógépek és az internet széleskörű elterjedésével, valamint a statisztika térnyerésével, az 1990-es évektől egyre meghatározóbbá, a következő évtizedekben pedig megkerülhetetlenné vált.
Mivel a napjainkat jellemző óriási és folyamatos adatrobbanás, a big data korában elképesztő mennyiségű adat keletkezik, feldolgozásuk, információvá alakításuk egyre kifinomultabb, gépi tanulás és automatizálás nélkül elképzelhetetlen megoldásokat igényel. Komputeres segítség nélkül az ember már nem tudna megbirkózni a feladattal.
A gépi tanulás típusai közül a mélytanulás (deep learning) a legismertebb. Lényege, hogy a nagymennyiségű gyakorlóadaton csiszolódó rendszer a kontextus függvényében, a korábbiaknál mélyebb tudásra szert téve, rétegről rétegre haladva a „mélybe”, ismer fel tárgyakat, állatokat stb., és tanul meg döntést hozni, például megállapítja, hogy az adott képen látható állat kutya és nem macska, vagy kikövetkezteti a következő szót egy szövegben.
Címkékkel lát el egyszerű képeket: például ha felcímkéz kellő számú (sok ezer vagy millió) olyan képet, amely lovat ábrázol, később nem csak felismerni lesz képes a lovakat, hanem meg is tudja különböztetni őket más állatoktól.
A mélytanuló algoritmusok programozás helyett következtetéssel, tapasztalataik alapján jönnek rá, hogy a ló nem azonos például a tehénnel. Egyre mélyebb szintekre ásó adatábrázolás kell hozzá: emlősökről, négylábú emlősökről, négylábú patás emlősökről van szó, és így tovább, végül kizárásos alapon, csak a ló marad.
 A gyakorlatban a gépi tanulás azért lehet sikeres, mert viszonylag egyszerű algoritmusok sok gyakorlás után is képesek komoly feladatokat végrehajtani. Például a rendszer kap egy adatbázist a páciensről és a cukorbetegségről, majd megfelelő mennyiségű tanulás után diagnosztizálja a bajt.
A gyakorlatban a gépi tanulás azért lehet sikeres, mert viszonylag egyszerű algoritmusok sok gyakorlás után is képesek komoly feladatokat végrehajtani. Például a rendszer kap egy adatbázist a páciensről és a cukorbetegségről, majd megfelelő mennyiségű tanulás után diagnosztizálja a bajt.
A technológia a hétköznapok részévé vált, az Amazon termékajánlója, a Netflix filmajánlóhoz, a Facebook és az X (az egykori Twitter) a felhasználónak megmutatásra kerülő bejegyzések kiválasztásához egyaránt gépi tanulást használ. Ezek az algoritmusok javasolnak könyveket, adnak tanácsot, hogy kivel randizzunk, és kivel ne, vagy éppen a meghirdetett állásra legalkalmasabb jelöltet is segítenek kiválasztani.
Frissítve: 2025. július 1.