A 20. század végétől a számítógépek a mindennapok meghatározó részei, a mai gazdaság és társadalom, életünk elképzelhetetlen nélkülük. Komputerünket azonban főként az operációs rendszeren keresztül látjuk, érzékeljük, az által kommunikálunk vele, és a perifériákon (monitoron, billentyűzeten, egéren) kívül a hardver rejtve marad előttünk.
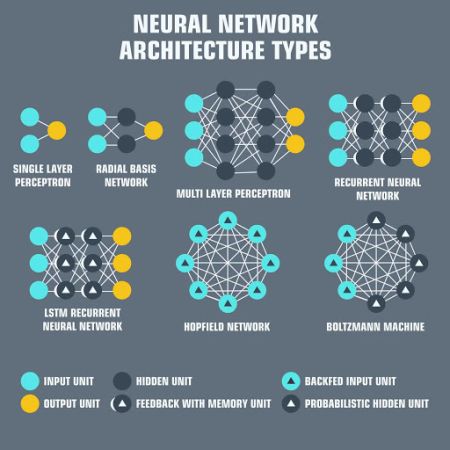
A rendszer sokkal összetettebb a látszatnál, bonyolultságában is kifinomult architektúrával szembesülünk nap, mint nap. Ha viszont az architektúra szóra gondolunk, computerek helyett törvényszerűen épületek jutnak eszünkbe. A párhuzam nem véletlen, mert a számítógép-architektúrában ugyanez az alapelv érvényesül – a tervezők úgy alakítanak ki egy komputert, rendszert, platformot, úgy illesztik egymásra a különböző elemeket, hozzák szinkronba őket, mint építész a ház változatos részeit.
A kifejezés bonyolultnak hangzik, definíciója azonban sokkal egyszerűbb, mint gondolnánk: a számítógépes architektúra a szoftver és a hardver közötti illesztési felületet, interakciókat, rajtuk keresztül a számítógépet működtető szabálysorokat jelenti. A szoftver- és hardvertechnológiai szabványok kommunikációját ez a specifikáció részletezi, belőle tudjuk meg azt is, hogy az adott gép milyen technológiákkal kompatibilis.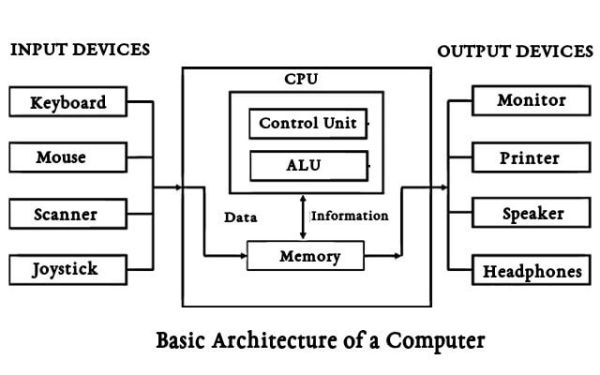 Az architektúra három főbb kategóriából áll.
Az architektúra három főbb kategóriából áll.
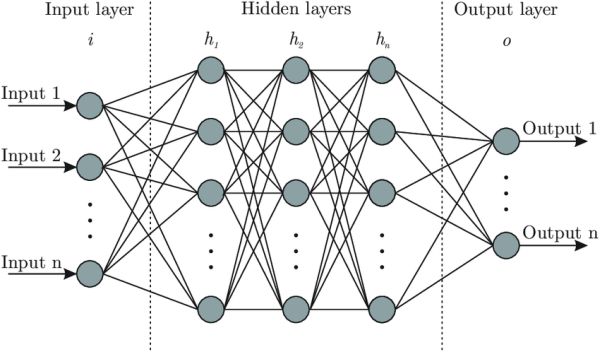
A rendszerterv, azaz az összes hardverrész, mint például a központi feldolgozó egység (CPU), az adat- és multiprocesszorok, a memóriakontrollerek és a memóriához közvetlen hozzáférést biztosító eszközök, a tényleges rendszer az első. Az utasítássorok architektúrája a második. A CPU funkciói és lehetőségei, programozási nyelve, az adatformátumok, a CPU és a mikroprocesszorok gyorsan írható-olvasható, ideiglenes tartalmú tárolóegységének (regiszterének) a típusai, és a programozók által használt utasítások, a rendszert működtető programok tartoznak ide. A harmadik, a mikroarchitektúra az adatfeldolgozó és -tároló elemeire, utasítássorokba történő implementálásukra vonatkozik. Ezeket a részeket együtt, meghatározott rend és minta alapján építik egymásra (mint a matrjoska babákat), hogy a rendszer pontosan és hiba nélkül működjön.
 A történelem első dokumentált számítógép-architektúrája a 19. századi feltaláló, Charles Babbage és Lord Byron lánya, Ada Lovelace levelezése a soha el nem készült analitikus gépről.
A történelem első dokumentált számítógép-architektúrája a 19. századi feltaláló, Charles Babbage és Lord Byron lánya, Ada Lovelace levelezése a soha el nem készült analitikus gépről.
A 20. században elsőként Konrad Zuse írta le 1936-ban, hogy hogyan képzeli el az első programvezérlésű, kettes számrendszerben dolgozó elektromechanikus computer, a Z3 működését.
Alan Turing szintén 1936-ban dolgozta ki az „absztrakt automata”, a digitális számítógép leegyszerűsített modelljének tekinthető Turing-gép elméleti alapjait. Rendszere három hardver- (memória, vezérlő, író-olvasófej) és egy, a gép működését irányító szoftveregységből áll.
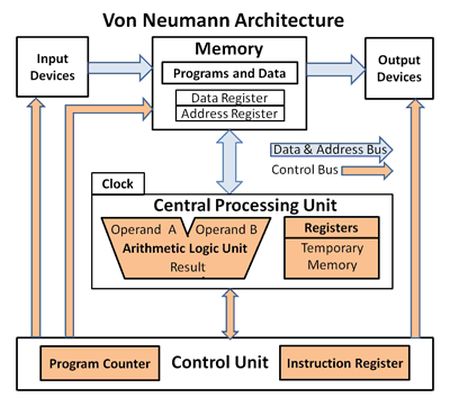
A Neumann János nevével fémjelzett, 1945-ben publikált tárolt programú számítógép modell alapján egy digitális komputer regiszterekből (aritmetikai és logikai műveleteket végző egységekből, azaz áramkörökből), a programszámlálót és az utasításregisztert tartalmazó vezérlőegységből (CPU), a számításokhoz szükséges adatoknak és az utasításoknak helyet adó operatív tárolóból (belső memóriából), háttértárból és a periféria ki- és beviteli mechanizmusaiból (input és output perifériákból) áll.

A Neumann-architektúrától a szintén az 1940-es években, a Harvard Mark I számítógéphez kidolgozott (azonos nevű), ma főként digitális jelfeldolgozó processzorokban és mikrovezérlőkben alkalmazott architektúra abban tér el, hogy az adatmemória és a program mindig elkülönül egymástól, a gép az adatmemória-hozzáféréssel egyszerre tud gyorsítótár nélkül is utasítást beolvasni és végrehajtani.
A legkorábbi architektúrákat papíron tervezték meg, majd közvetlenül építették a hardverbe. Később fizikailag is létrehozták, tesztelték, a végleges változatig módosították a prototípusokat. Az 1990-es évektől ezeket a műveleteket általában más architektúrák belsejében, architektúraszimulátorral végzik.
Frissítve: 2025. június 8.


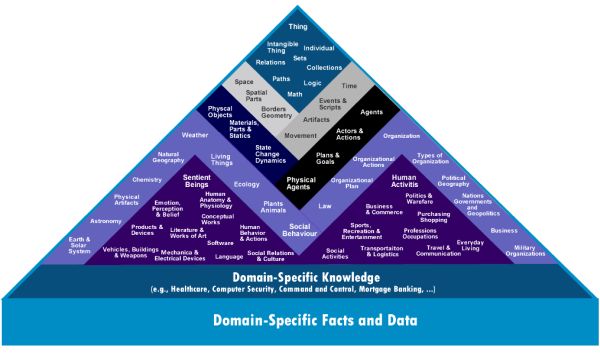
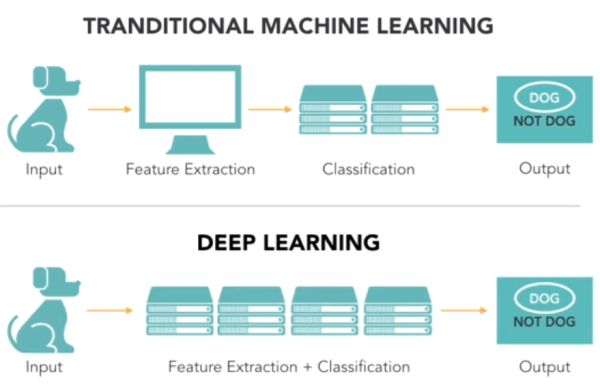
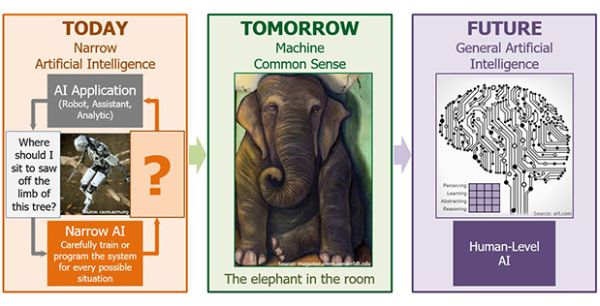 Mostanában többen próbálkoznak a klasszikus józanész-megközelítés és a mélytanulás fúzióján, születnek részsikerek, és bizakodnak, hogy eredményesebbek lesznek.
Mostanában többen próbálkoznak a klasszikus józanész-megközelítés és a mélytanulás fúzióján, születnek részsikerek, és bizakodnak, hogy eredményesebbek lesznek.