Az éghajlatváltozást, a globális felmelegedést emberi tevékenységek idézték elő, és úgy tűnik, hogy inkább csak lassítani tudjuk, mintsem megállítani, visszafordítani a klímakatasztrófához vezető folyamatokat. Ez már nem a jövő, hanem a jelen; fenyegető jeleit egyre gyakrabban érezzük, és szép szólamok mellett, ideje lenne komolyabban cselekednünk is, hogy a fejlődés valóban fenntartható legyen.
Városainkban – ha megengedhetjük magunknak – folyamatosan nő az életminőséget javító lehetőségek száma. Ezzel párhuzamosan a lakosságszám is évről évre emelkedik, és az igények kielégítésére, állami és magánszervek lakókörnyezetünket infokommunikációs és más csúcstechnológiákkal igyekeznek élhetőbbé és intelligensebbé tenni. A mindenhonnan összegyűjtött adatokkal, megfelelő felhasználásukkal újabb megoldások nyílnak javaink és erőforrásaink kezelésére.
Az IT termékek és alkalmazások növekedésével, a gyártásuk iránti igény is állandóan nő. Hosszú távon viszont csak akkor hasznosak ezek a folyamatok, ha a termelés minden szintjén érvényesítjük a természetvédelmi elveket. A zöld informatika, vagy zöld számítások néven is ismert zöld IT ezeknek a termékeknek és alkalmazásoknak környezetbarát módon történő előállítására vonatkozik.
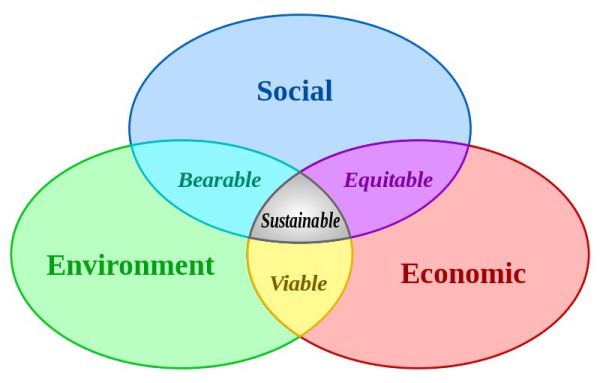
A koncepció nem új, érvényesítése viszont sokkal sürgősebb, mint volt valaha is. Első megvalósulása az Egyesült Államok Környezetvédelmi Ügynökségének 1992-ben indult, az energiahatékonyságot elismerő, promótáló, a döntéshozásnál ezt figyelembe vevő vállalatokat anyagilag is segítő Energy Star programja volt. Eleinte csak a hardverre összpontosítottak, szerencsére ma már a teljes IT-ökológiaban – gyártásban, fogyasztásban, újrahasznosításban – gondolkozunk. A zöld IT minden infokommunikációs termék és alkalmazás egész életciklusra vonatkozó negatív környezeti hatásainak a minimalizálását célozza. Hatékony alkalmazásával nemcsak az intelligens város, hanem az egész bolygó fejlődése fenntarthatóbb.
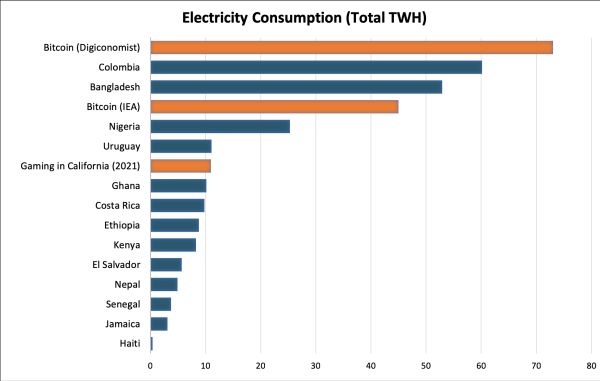
Az intelligens technológiák, például a kriptovaluta-bányászat viszont drágák és sokat fogyasztanak, az erőforrások túlzott használata inkább fenntarthatatlansághoz vezet. Egy számítógép életciklusában elfogyasztott természetes erőforrások 70 százaléka a gyártáshoz kapcsolódik, ráadásul ezek a termékek sokkal hamarabb elavulnak, mint akárcsak egy évtizede – kézenfekvő megoldás a hosszabb életciklusra tervezés, biológiailag lebomló, újrahasznosítható anyagokban gondolkozni. A szoftverek, a hálózati alkalmazások és a megkerülhetetlen adatközpontok szintén széndioxid-kibocsátással járnak.

De mit tud mindezzel kezdeni a zöld IT? Szerencsére sokat, például virtualizáljuk a számítógépet, szervereket, azaz a rendszeradminisztrátor több komputert egyetlen robusztus rendszeren virtuális géppé kombinál egybe, és az eredeti hardverek kiiktatásával jelentősen csökken az energiafelhasználás.
A katódsugaras monitorokat (CRT) váltó folyadékkristályosokban (LCD) jóval kevesebb az ólom, a kapcsolódó LED-ek (fénykibocsátó diódák) szintén zöld megoldások, mert nem tartalmaznak a környezet és a Homo sapiens egészségére egyaránt káros higanyt.
A fizikai „ottlétet” kiiktató telekonferenciával, telejelenléttel és a koronavírus-járvánnyal felpörgött távmunkával, vagy az energia számítógépek igényeinek megfelelő kiosztásával, feszültségmentesítéssel csökken a károsanyag-kibocsátás. Leselejtezett számítási eszközeink újrahasznosításával szintén kevesebb ólom és higany kerül a környezetbe, és mivel teljesen új gépet sem kell gyártani, a széndioxid-lábnyom is kisebb.
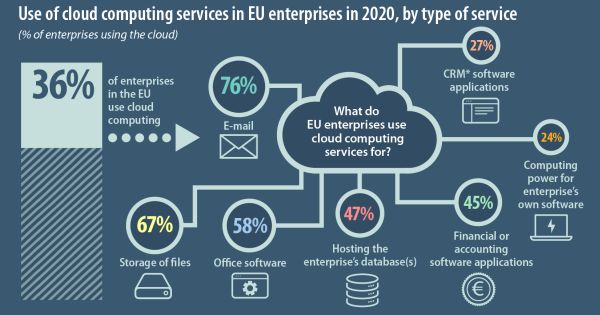
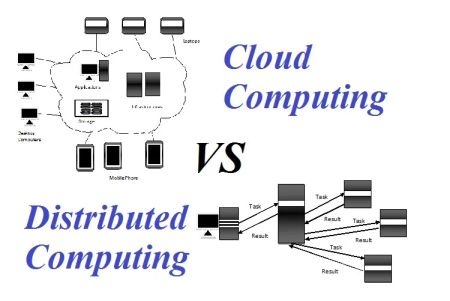
A felhőszámítások szintén fontos szerepet játszanak a zöld IT-ben. Nagy- és kisvállalatok helyszíni alkalmazásaik felhőbe költöztetésével akár a felére csökkenthetik az energiafogyasztást és a széndioxid-kibocsátást. Tegyük mindezek mellé az infokom nagyvállalatok (Google, Microsoft stb.) folyamatos vállalásait a zéró károsanyag-kibocsátásról, a médiahasználat optimalizálását, a felesleges papírnyomtatás csökkentését (legalábbis a lehetőségét), és máris egy kicsit, de csak nagyon kicsit zöldebbnek látjuk a jövőt.
Frissítve: 2023. december 26.